
Demystifying Concurrency across programming languages
TLDR;
Let's try to uncover how different programming languages tackle concurrency problems in a different style. What are the trade-offs from Goroutines in Go, to Async/Await in C# and JS, to the latest changes happening in Rust and Java. We'll review also the different programming styles and the impact on complexity and maintenance for developers
Concurrent programming an its inherit complexity
A big part of the applications that we deploy everyday relay on exchanging data, either with other systems or from devices where is running, like disks. So, depending on the use case, a big part of the execution time is just waiting for those resources to be available, in order to process and present them, these waiting periods lead to some inefficiencies.
This is how 2 requests will be processed without concurrency by a single thread.
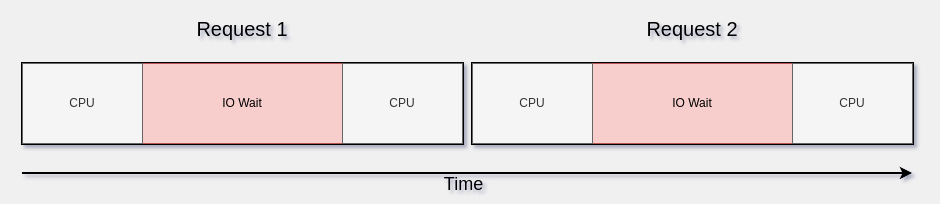
However, if we can process these requests concurrently, we can do some work while we wait for the data to be ready
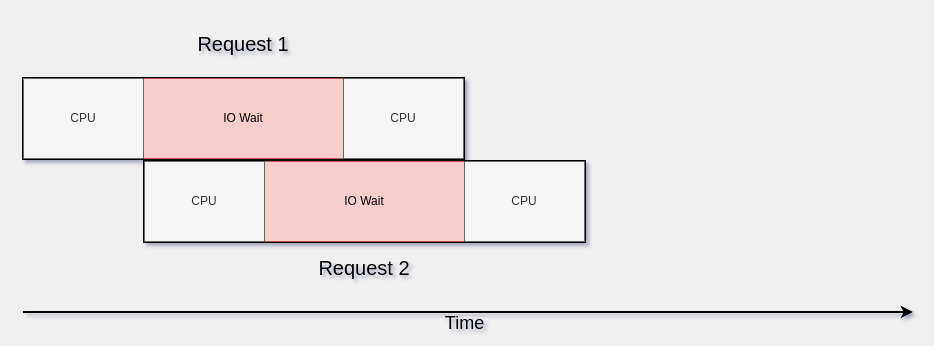
As we can see, we improved some of the inefficiencies processing those requests concurrently, by overlapping some of the work of the 2nd request in the same thread while we wait for the data to come back for request 1.
Most of the languages have solved these issues by creating more OS threads and managing a pool of them to schedule the work, so that when a thread is blocked we can still continue the execution in a different one from the pool. The problem with this is that creating OS threads is quite expensive in terms of resources, specially memory, so creating many of them tends to lead to high memory usage or out of memory exceptions. The demand for more processing has been scaling quite rapidly, so something had to change to be able to efficiently offer the services required on a modern age.
So if we can't really relay on OS threads to achieve the needs on high concurrency and parallelism required by modern systems, what are the alternatives available then.
There are two main issues that need to be solved:
- Avoid blocking the OS thread while we wait for resources to be ready, so that other work can be scheduled.
- Synchronize data modifications across shared structures if needed.
Different programming languages approach these in a different ways as we will see.
Async/Await - Stackless coroutines
Asynchronous programming was introduced by F# in 2007 and it quickly spread across many languages like C#, JS/TypeScript, Python... Let's see an example on how to using async/await in C#
async Task Run() {
var content = await ReadFile();
Console.Write(content);
}
async Task<string> ReadFile() {
var content = await File.ReadAllTextAsync("some_file.txt");
return content;
}
As we can see, the functions are decorated with the async keyword and return a Task, Future, Promise... this in essence, allows the compiler to interpret and change the bytecode to avoid blocking the thread while we wait for IO, yielding the execution to other coroutines while we wait for resources.
The compiler does this, by generating a state machine which can maintain the status of the execution to be able to resume the work. So that when we the data is ready we can restore the previous state of the function and continue with the execution on the same or different thread. This is the reason they are called stackless coroutines, as they can only be resumed on the async/suspend functions that generate the state machines as they don't persist the whole stack trace.
Stackless coroutines have proven quite popular, mainly as it generates efficient state machines which only hold the necessary data to be able to resume the work. This has lead to a quick adoption across many languages: C#, Python, JS/TypeScript, Rust, Kotlin...
Although this approach is very efficient, there are some sacrifices by choosing this path:
- The method syntax has changed, and the new async/suspend methods can only be consumed from an async method function (if you don't want to block)
- It has as a cascade effect over any existing framework or libraries that want to adopt the new model, once a method is changed the whole stack trace needs to be rewritten to accommodate the async model. If you had to do some of this migration will understand the pain.
- Usually you have to maintain two sets of APIs for asynchronous and synchronous execution, increasing the maintenance effort.
- This API duplication have a big impact on a language ecosystem. First the standard libraries/framework needs to support this scenario adding the new APIs, and from then other libraries can start expending their APIs to accommodate this new paradigm. Not every API will be able to adapt to this, leading to a mixed ecosystem.
- Only on these functions decorated with await or suspend, you can have yield points to pause and resume the execution, liberating the thread for other work.
Is there a different way?
Goroutines - Stackful coroutines
The Go language was released in 2007 and with it the introduction of Goroutines or Stackful coroutines. Some of the language design philosophy is clearly reflected in Goroutines, which allowed Goroutines to achieve: security, performance but without sacrificing simplicity. As we will see in the example below, you can develop as if a normal synchronous execution its taken place, you can do this as Goroutines are cheap to create as opposite to OS threads, while they look the same from a Developer point of view.
Goroutines are scheduled on OS threads for execution, and they can be moved from one thread to another as needed by the scheduler making full usage of the multiple cores to achieve parallelism.
In contrast to stackless coroutines, stackful coroutines maintain the stack frames of the execution which allow it to be paused and resumed at any point of the execution, hence the name. Let's see an example:
func Run() {
ch := make(chan string)
go func() {
ch <- ReadFile()
}()
content := <-ch
fmt.Print(content)
}
func ReadFile() string {
content, _ := os.ReadFile("some_file.txt")
return string(content)
}
As we can see on the example, there are some differences with the async/await approach. Any function can be called as a goroutine, the go keyword in essence creates a virtual thread to run the function, a goroutine. There is no need to mark them as async or change the return type for the compiler to do any transformation. It is up to the function making the call can decide if it wants to run it on the same or different goroutine depending of its use case. This is a significant advantage as with a single API, you can easily allow to execute the code concurrently or not.
Let's try to summarize the benefits and drawbacks compared with the previous approach, some of its benefits are:
- Maintain a single API for sync and async execution
- The caller to the function can decide to run on the same or different goroutine.
- Most of the time, you can program as if a synchronous execution is taking place without having to worry, as this is mostly hidden from the Developer and is part of the framework scheduling the work.
However there are some drawbacks
- The stack frame needs to be persisted to be able to pause and resume, as opposite to state machines which are perfectly optimized.
- The stack frame needs to be initially allocated and potentially expanded and copied over as needed.
- Integration with foreign languages has added extra complexity as things don't run on OS threads. This is more a Go issue than of Stackless coroutines as everything runs as Goroutines.
It seems that this approach reduces the API surface and it makes easier to reason treating all the code as synchronous without having to worry avoid blocking a thread for Developers. This arguably adds more complexity to the runtime implementation as you need virtual stacks that potentially need to be resized, probably a reason why this is not as spread as stackless coroutines.
On the negative side we see that stackfull coroutines are not as efficient as they have to persist the stack frames, rather than a perfectly optimized state machine, but is it this a deal breaker? If that was the case Go will be known as a slow language and not being very memory efficient, however we can see the opposite, leading the performance in GC languages and with a significant decrease in memory usage compared with the others. This is due to some smart optimizations in the way Go works internally, inlining functions to reduce stack frames depth, favouring stack variables over heap allocation which incur indirection, as opposed to Object oriented languages, memory efficient structs.... It is easy to be fooled by the simplicity of Go when looking at the code, but taking a look at the results it's clear that there are many smarts optimizations, however this is out of the scope for this post.
One last thing to highlight on the Go code, it's the usage of channels to synchronize the execution and to return the value to the calling goroutine. This is other of the design elements of Go to avoid data races, where you should share by communicating, using channels, and not communicate by sharing memory, by sharing memory structures, which leads to synchronization issues, locking contention and data races. This also lead to most of the time being able to avoid having to design concurrent data structures and a more simple API.
Why bring this now?
Apart from Go taking a different route it seems the other languages have taken the route of stackless coroutines, until project Loom in Java decided that is using the same path of Go by creating virtual threads, the equivalent of Goroutines. The virtual threads will be a preview feature on the JDK 19.
The decision for Java to take this route has probably to do with evaluating the impact of incorporating something like async/await on the SDK and the Java ecosystem, that is certainly not an easy feat. Java had other paradigms based on Reactive programming, but never seem to took off due to having a bigger impact on API design and Development complexity. Go has demonstrated that efficient stackful coroutines can be achieved, without sacrificing development and maintenance.
More interestingly in Java, it is that the JVM is shared with other languages like Kotlin, which implemented stackless coroutines as it couldn't do in any other way without support on the JVM for stackful coroutines. So this is something to keep an eye on and see how Kotlin will be affected by this change in the next years, once Loom matures.
On the Rust side, there has also been some arguments about the problems that async/await brings, although being a language that favours zero cost abstractions over complexity, as opposed to Go, the stackless approach seems to be winning. Despite that, there are alternatives like May, which are possible, due to Rust being a very powerful language that allows you to do almost everything and in a secure way.